


Convolutional Neural Networks in Deep Learning
What is Convolutional Neural Network?
Convolutional neural networks are a model of deep learning that mainly processes tasks such as images and videos. CNN has achieved great success in the field of computer vision, such as multi object tracking, object recognition, image retrieval, and other research directions. Of course, it has also achieved good results in natural language processing, speech recognition, and other fields.
What is Convolution?
Convolution is a mathematical operation that combines two functions to produce a third function. In the context of signal processing and neural networks, convolution refers to the process of applying a filter (also known as a kernel or convolutional kernel) to an input signal or image. This operation involves sliding the filter over the input data and computing the element-wise multiplication of the filter values and the overlapping input values, followed by summing up the results.
The mathematical representation of convolution operation is as follows:
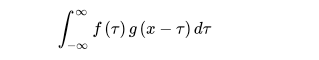
What does Convolutional Neural Network include?
Key features of CNN include convolutional layers, pooling layers, and fully connected layers:
Convolutional Layer: The convolution operation is at the core of CNN. Through this operation, the network can detect spatial local patterns in the input data, such as edges and textures. Convolutional layers use learnable filters (or kernels) and perform convolution operations by sliding them over the input data.
Pooling Layer: Pooling operations are employed to reduce the spatial dimensions of the output from convolutional layers, decreasing computational complexity and enhancing the network’s robustness to spatial variations. Common pooling operations include max pooling and average pooling.
Fully Connected Layer: Typically found in the last few layers of the network, fully connected layers transform the feature maps extracted by convolutional and pooling layers into the model’s output. These layers are densely connected to all neurons in the preceding layer, forming a dense connection structure.
The Working Process of Convolutional Neural Networks.
1.Extracting Image Features.
The method employed by convolutional neural networks to extract features from images involves using a relatively small matrix, referred to as a convolutional kernel. The kernel traverses the image matrix from left to right and top to bottom in a step-by-step manner. At each position where the kernel aligns with the image values, the individual values of the kernel matrix are multiplied with the corresponding values in the image matrix. The results are then summed to obtain a new value. By iteratively moving the convolutional kernel and performing these calculations, a new matrix, termed a feature map, is generated. This feature map can be considered as an image matrix and is often referred to as a “feature map image,” or simply a “feature image.” The obtained feature image is stored in the next layer, known as the convolutional layer, which can be thought of as analogous to the hidden layer in a multi-layer perceptron. Feature extraction is commonly understood as preserving the primary information in the image, such as object contours and textures, while eliminating unnecessary redundancies.
Here is a simple computation process:
Assuming the input image matrix is
1 1 1 1
1 1 0 1
1 1 1 0
1 0 0 1
1 0 1 1
Convolution kernel is:
1 0 1
1 1 0
0 0 1
The computation involves the convolution kernel starting from the top-left corner of the image matrix, moving from left to right and top to bottom. As it moves, the convolution is calculated. The result below represents the matrix of the first feature map obtained through the convolution operation on the input image matrix:
5 3
3 6
4 2
The role of the convolutional kernel is akin to a feature extractor, capable of extracting features from a local region of an image. Different convolutional kernels function as distinct feature extractors. To capture multiple features from an image, it is common to use multiple different convolutional kernels and perform convolution operations several times, resulting in multiple feature images. In other words, the convolutional layer following the input layer typically includes multiple feature map images.
It is important to note that while the example here uses fixed convolutional kernels, in practice, these kernels are computed, and bias values are often added during the computation process.
2.Activation Function
The operations described above are purely linear, yet most real-world problems are predominantly nonlinear. Therefore, similar to a multi-layer perceptron, after the convolutional processing, it is common to introduce a nonlinear operation. Each piece of data obtained is typically subjected to an activation function to make the data more representative of real-world problems.
For example, a commonly used activation function is ReLU (Rectified Linear Unit), and its function graph is shown below: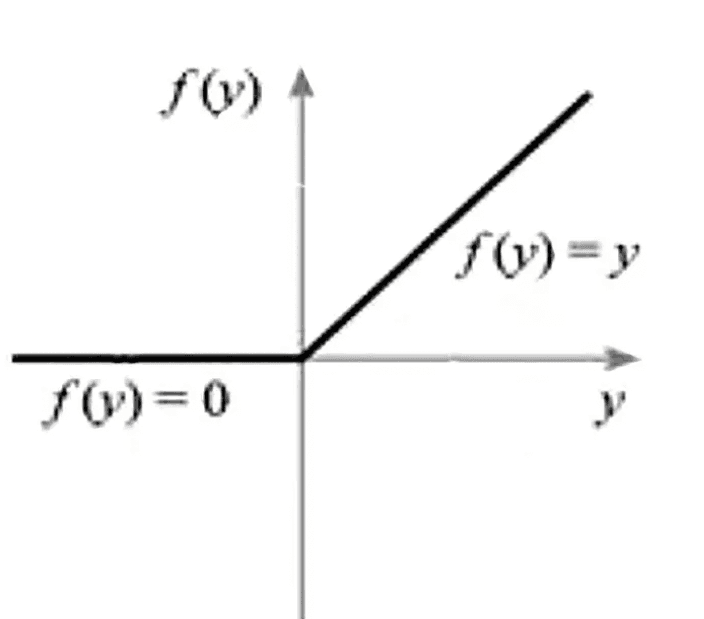
According to the function graph, it can be observed that all negative parts yield zero, while positive values remain unchanged. For example, as shown in the graph below: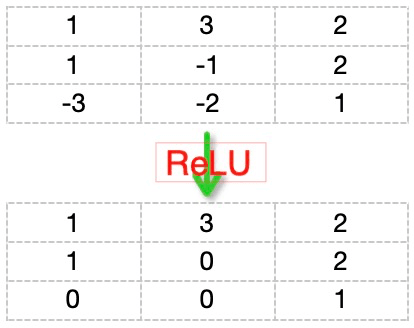
Pooling Layer
The purpose of the pooling layer is to reduce the number of values in the feature image and decrease the size of the feature map image.
Assuming that after ReLU processing, the obtained feature image is:
2 3 8 1
1 3 6 3
9 0 1 7
4 2 3 9
Pooling processing is applied to the feature image, requiring the setting of two hyperparameters: the filter size (F) and the stride (S). Here, assuming F=2 and S=2, “max pooling” retains the maximum pixel value within each 2*2 (i.e., 4) pixel region, discarding the other three pixel values. As illustrated below: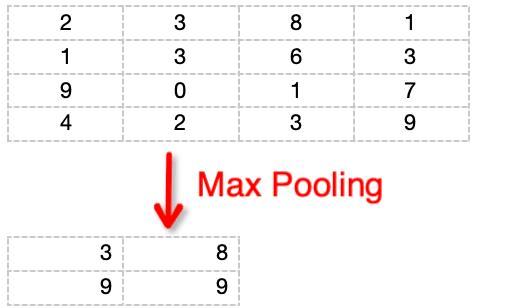
In this way, through “pooling” processing, a 44-sized image is reduced to a 22-sized image.
The aforementioned steps constitute a convolutional block, and by passing through two fully connected layers, an RNN can then receive input sequences and generate corresponding output sequences.