


1.Introduction
In most cases, we use redis stand-alone service. In actual scenarios, single-node Redis is prone to risks.
Since failover cannot be achieved, subsequent requests will be sent directly to the database. A large number of queries will cause the number of database connections to reach a peak, and internal lock conflicts will be serious, resulting in slow queries, connection timeouts and other consequences. So at this time, can we deploy multiple copies of the data to other nodes for replication, and when a failure occurs, quickly manually switch the connected Redis?
Of course, Redis provides us with this function.
The master-slave mode can redundant the data of the master node to multiple slaves. When combined with the sentinel mode, it can quickly detect the master failure and perform master-slave switching to achieve failover.
2.Master-slave mode
The master-slave mode can be divided into one master and one slave, one master and multiple slaves, and master-slave structures. No matter what the structure is, the common point is that each slave node will copy the data of the master node to achieve data backup.
- One master and one slave: When the master node fails, the slave node becomes the master node and continues to serve.
- One master and multiple slaves: This method usually separates reading and writing in Redis. The master node is only responsible for write requests, and all query requests are distributed to each slave node, which will greatly improve the throughput of Redis. We can also use one master and multiple slaves to place time-consuming commands on any slave node. This can effectively prevent slow queries from blocking the master node and thus affecting the stability of the Redis service.
- Master-slave: Slave2 is not the direct slave node of the Master, but an indirect slave node. In this way, Slave2 does not need to request the Master to copy data, but only needs to request Slave0. This method can effectively reduce the workload of the Master node.
3. Master-slave replication principle
Redis uses the master-slave synchronization of data completed by the psync command at the bottom layer during replication. Synchronization is mainly divided into two types: full replication and incremental replication.
Full replication: As the name suggests, it means sending all the master node data to the slave node at one time. Therefore, in this case, when the amount of data is relatively large, it will cause a lot of overhead on the master node and the network.
Partial replication: Used to deal with data loss scenarios due to network interruptions and other reasons during master-slave replication. When the slave node connects to the master node again, the master node will resend the lost data. Because it is a reissue, the amount of data sent must be less than the full amount of data.
4. Full copy
The full copy diagram is as follows:
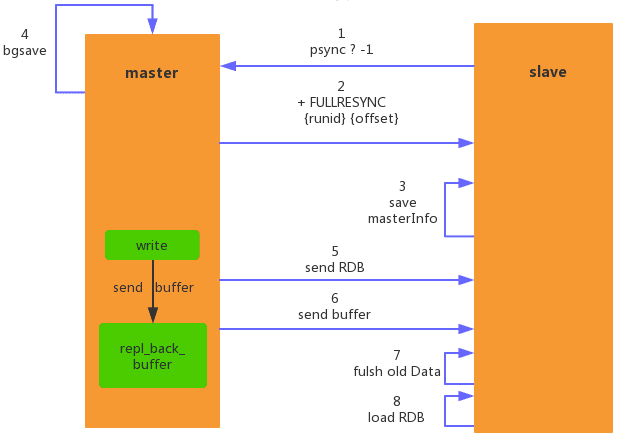
Full copy is the earliest replication method supported by Redis. The commands that trigger full copy are sync and psync. Below we introduce the process of full replication in Redis:
- Send the psync command for data synchronization. Since this is the first time to replicate, the slave node does not have the replication offset and the master node running id, so send psync? -1.
- After the master node receives the command from the slave node, the master node parses the current full copy according to psync ? -1, so it replies +FULLRESYNC. At the same time, it also sends its own runid and offset offset to the slave node, and the response is +FULLRESYNC { runid}{offset}.
- After the slave node receives the response from the master node, it will save the runid and offset of the master node.
- The master node executes bgsave to save the RDB file to the local. The master node sends the RDB file to the slave node. The slave node saves the received RDB file locally and directly uses it as the data file of the slave node. After accepting the RDB file, the slave node prints the relevant logs.
- From the time when the slave node starts to accept the RDB file to when it is completed, the master node still responds to the read and write commands, so the master node will save the write commands during this period in the client’s buffer. After the slave node loads the RDB file, the master node will The data in the area is sent to the slave node to ensure data consistency between the master and slave. If the data transmission time of the RDB files between the master node and the slave node is too long, the above analysis may cause buffer overflow on the client side. The default configuration is client-output-buffer-limit slave 256MB 64MB 60. If the buffer consumption exceeds 64MB or 256MB within 60 seconds, the master node will directly close the client connection, causing full synchronization to fail.
- After the slave node receives all the data sent from the master node, it will clear its own old data.
- After clearing the data from the node, start loading the RDB file. If the RDB file is large, this operation is also time-consuming.
- After the RDB file is successfully loaded from the node, if the AOF persistence function is enabled on the current node, it will immediately perform the bgrewriteaof operation to ensure that the AOF persistence file is immediately available after full replication.
The main time-consuming aspects of full copy are as follows: - The master node uses the bgsave command to fork the child process for RDB persistence. This process consumes a lot of CPU, memory (page table copy), and hard disk IO.
- The master node sends the RDB file to the slave node through the network, which consumes a lot of bandwidth on the master and slave nodes.
- The process of clearing old data and loading new RDB files from the node is blocked and cannot respond to client commands; if bgrewriteaof is executed from the node, additional consumption will also be incurred.
In other scenarios, full copying should be avoided as much as possible. Due to various disadvantages of Redis full replication, Redis provides partial replication functions.
5.Partial copy
Part of the copy diagram is as follows: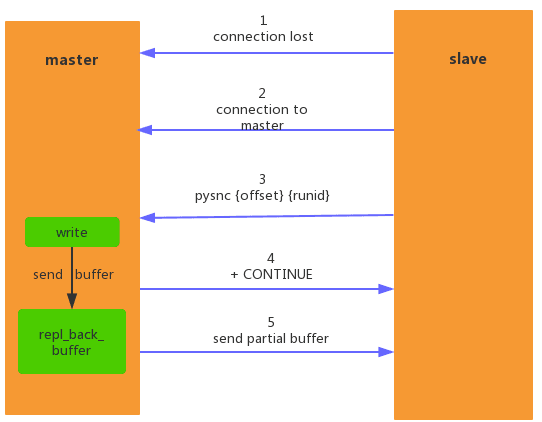
Partial replication is mainly an optimization measure made by Redis against the excessive overhead of full replication. It is implemented using the psync{runId}{offset} command. When the master-slave node has a network interruption at the command propagation node and data loss occurs, the slave The node will request the master node to send the lost data. If the requested offset is in the replication backlog buffer, the master node will resend the remaining data to the slave node to keep the data of the master and slave nodes consistent. Due to the reissued data Generally, it will be relatively small, so the overhead will be very small compared to full copy. The process is as follows:
- When the network between the master and slave nodes is interrupted, if the repl-timeout time is exceeded, the master node will consider the slave node to be faulty and interrupt the replication connection.
- Since the master node is not down, it will still respond to client commands. However, the command cannot be sent to the slave node due to the interruption of the replication connection. However, the master node will internally save the commands during this period in the client buffer. The default size is 1MB.
- When the master-slave node network is restored, the slave node will connect to the master node again.
- When the master-slave node connection is restored, the slave node has previously saved its own offset and the running id of the master node. Therefore, they are sent to the master node as psync parameters, requiring a partial replication operation.
- When the master node accepts the psync command from the slave node, it will first check whether the requested runid is consistent with its own runid. If it is consistent, it indicates the current master node replicated by the slave node. Then check whether the requested offset is in the copy backlog buffer. If it is, perform partial copy. Otherwise, perform full copy. Partial copy will reply +continue response and accept the reply from the node.
- When performing partial replication, the master node only needs to send the data in the replication backlog buffer to the slave node according to the offset to ensure that the master-slave replication enters a normal state.
6.Heartbeat
In the command propagation phase, in addition to sending write commands, the master-slave node also maintains a heartbeat mechanism: ping and replconf ack. The heartbeat mechanism plays a role in master-slave replication timeout determination, data security, etc.
- The master and slave nodes have heartbeat detection mechanisms for each other, and each simulates the other party’s client to communicate. Use the client list command to view the replication client information. The connection status of the master node is flags = M, and the connection status of the slave node is flags = S.
- By default, the master node sends a ping command to the slave node every 10 seconds to determine the survival and connection status of the slave node. The sending frequency may be modified through the repl-ping-slave-period parameter.
- The slave node sends the replconf ack{offset} command every 1 second in the main thread to report its current offset to the master node.
7.Summarize
This article mainly explains the replication principle between master-slave replication, which is divided into: full replication and partial replication. Master distinguishes between full copy and partial copy, relying on the runid and offset parameters.
For the first copy, a full copy is performed. The Master generates an RDB file and stores the subsequently generated commands into the copy backlog buffer. After the slave is disconnected and reconnected, the master selects the starting byte for transmission in the copy backlog buffer based on the offset. If not found, make a full copy.