The CAP theorem is a common criterion used by engineers to measure the design of distributed systems. The CAP theorem holds that a network-based data sharing system can only satisfy at most two of the three elements of data consistency, availability, and partition tolerance; during the system design process, engineers can only guarantee the second and choose optimization.
source
The CAP theorem (CAP theorem) was first proposed by Brewer (Eric Brewer) in the fall of 1998, officially published in 1999, and was the subject of the Symposium on Principles of Distributed Computing (PODC) conference in 2000. lecture; in 2002, Seth Gilbert and Nancy Lynch of MIT published a proof of Brewer’s conjecture, making it a theorem and thus Called Brewer’s theorem (Brewer’s theorem).
CAP theorem
- Consistency, which is equivalent to all nodes accessing the same latest data copy;
- Availability (Availability), with high availability for data updates (reading and writing);
- Partition-tolerance is to quickly ensure data consistency and availability of all network partitions under certain time conditions.
CAP theorem derivation
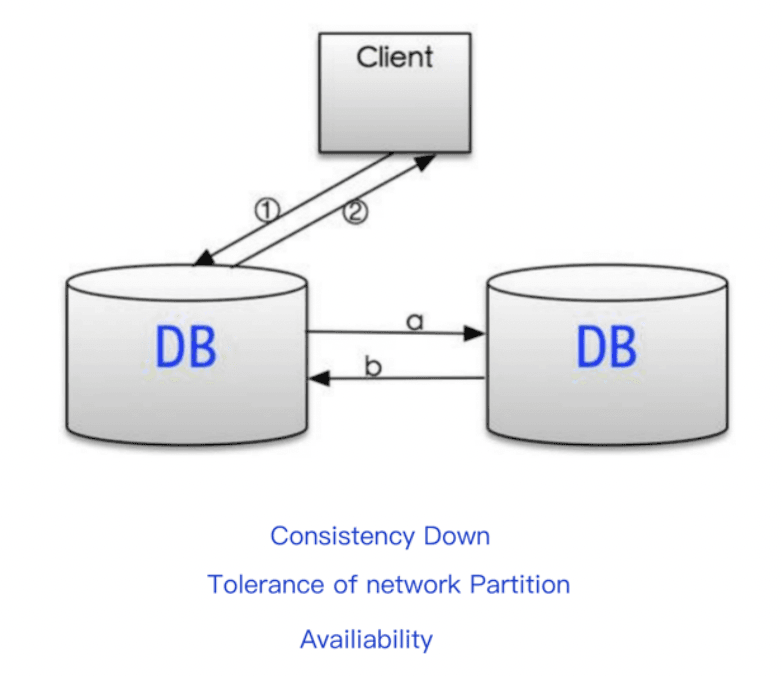
High availability and data consistency are the goals of many system designs, but partitioning is unavoidable. The following demonstrates with database design, using Professor Brewer’s original distributed scenario as WebService, database DB as Server, and user as Client.
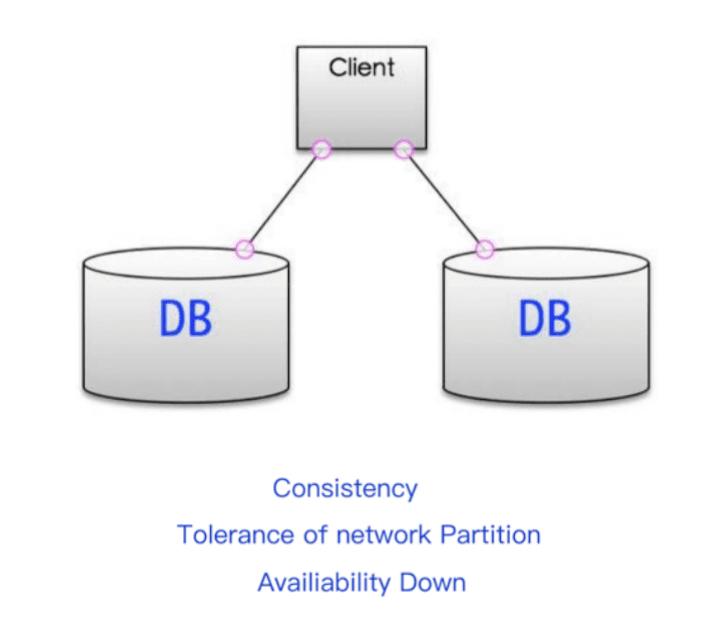
CP without A
If A (available) is not required, it means that each request needs to be strongly consistent between servers, and P (partition) will cause the synchronization time to be infinitely extended, so CP can also be guaranteed. Many traditional database distributed transactions belong to this mode. Such as the singleton mode of MySQL, Memcached, Redis, etc., which are common in early and early websites.
As shown in the figure, there is no inconsistency problem in data reading due to network partitions, so there is no partition synchronization problem, but if the database fails, data availability cannot be guaranteed.
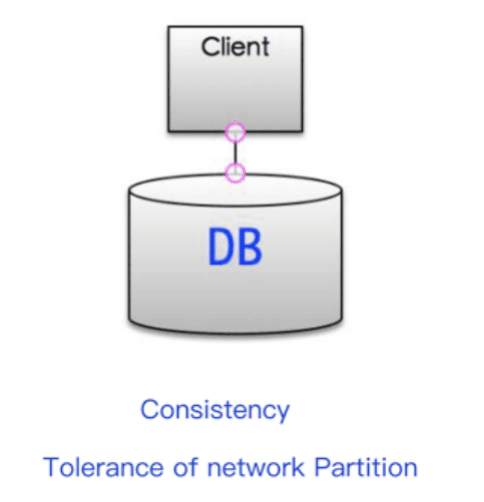
How to optimize availability (Availability)?
Sharding storage uses some Hash algorithms such as (consistency Hash) to store data in shards, which is common in the sharding design of MySQL databases, as shown in the figure below.
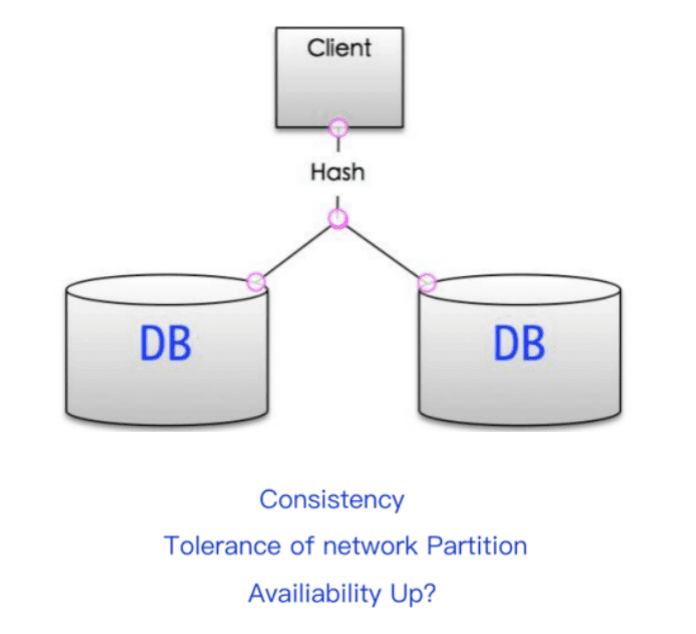
- Since the data is stored in pieces in each database, data consistency can still be guaranteed;
- Since the databases do not communicate with each other and do not depend on each other’s existence, partition tolerance is still not broken.
- The availability remains unchanged; assuming that the cluster has two servers and the data is evenly distributed, the probability of our database instance going down is P. Then the availability of this cluster that uses hashing for data sharding is:
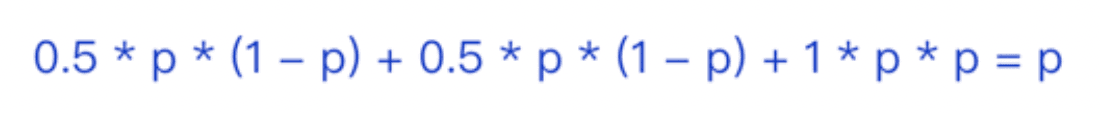
Usability optimization points:
The downtime of a single server will only lead to service degradation, not all unavailability.
The cluster has the possibility of expansion and contraction, with scalability (Scalability)
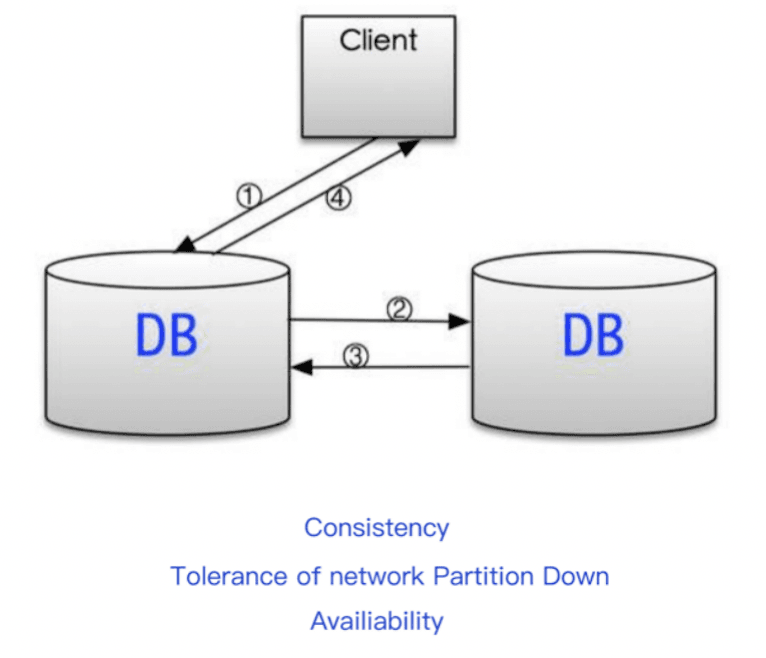
CA without P
If P (partition not allowed) is not required, then C (strong consistency) and A (availability) are guaranteed. But in fact, the problem of partitioning always exists, so the CA system is more to allow each subsystem to still maintain CA after partitioning.
How to provide better availability in multi-copy write mode? A common solution is to write to multiple databases at the same time when writing to the database. When multiple databases are written successfully at the same time, it is considered successful. This will reduce the availability of data writing.
Assuming that the failure rate of the stand-alone database is p (p<1.0), then the availability of the stand-alone database is 1-p. The summary is:
Write scenario: Consistency (C) and partition tolerance (P) have not changed, but availability (A) has decreased, from 1-p to 1-2p-p2
Read scenario: Consistency (C) and partition tolerance (P) remain unchanged, availability (A) has increased, from 1-p to 1-p2
Therefore, it is more suitable for “read more and write less” scenarios, such as video and news services, the captured data is generally only written once, but requires many reads.
AP wihtout C
To be highly available and allow partitioning, you need to give up consistency. Once a partition occurs, the nodes may lose contact. For high availability, each node can only provide services with local data, which will lead to inconsistency of global data. Many NoSQLs now fall into this category.
In multi-copy mode, it returns only after multiple copies are successfully written. In this way, the consistency (C) is still guaranteed. But write availability (A) and partition tolerance (P) will decrease compared to a single machine. in exchange for
Relatively simple API, the client does not need to pay attention to the “multiple write” problem (but often put the synchronization on the server side, such as the master-slave synchronization of the database)
High availability (HA) for read operations
Since the needs of most Internet companies do not require strong consistency (C), achieving higher availability (A) and partition tolerance (P) by giving up consistency has become the core idea of most NoSQL databases currently on the market.