


Yuncheng Liao
Technology Center, Surfin Group
Abstract
The emergence of large language models (LLMs) such as GPT, Llama, and BERT has led to the incredible accumulation of knowledge and natural language abilities. Practitioners from various fields are exploring the practical applications and scenarios of LLM within their specific domains. This article introduces the KBGPT, a question and answer system based on large language models recently developed by the technology department. The system utilizes a contextual question and answer format, avoiding issues related to fine-tuning and training models: 1) the need for manual preparation of pre-labeled sample data; 2) the requirement of resources to conduct training; and 3) the necessity of maintaining resultant models. The primary principle involves storing existing business knowledge documents of the company in blocks, followed by utilizing semantic-based similarity matching methods to enable each question to automatically match relevant knowledge context. In addition, Zero Shot + Chain of Thought was employed to construct prompt words. Currently, KBGPT is based on ChatGPT but not limited to it, as open source alternatives like Vicuna13b can also be employed. In addition to the Q&A process, KBGPT incorporates a cache mechanism based on question similarity to achieve repeated utilization of similar questions. The system has already been introduced into the production environment, running well and meeting requirements. To cater to the company’s strategic layout for AIGC, this article summarizes KBGPT’s experiences and lessons learned in the latter part while proposing specific and feasible plans for AIGC.
1. Introduction:
Recently, ChatGPT and LLM have emerged as more powerful tools for empathizing, universal values, and logical reasoning skills that enable businesses to better interact with customers. Although ChatGPT does not possess domain-specific business knowledge, the model can learn relevant business information through fine-tuning and training. This method requires pre-prepared data labeled in advance and trained to generate new models familiar with business knowledge. However, experiments have shown that the prompt word can easily bypass the content of training and induce models to answer unrelated content, which is a limitation of fine-tuning models on its own.
LLM cannot avoid one problem for the time being which is factual errors, and this is a fatal issue in customer service systems related to brand image. Other problems that exist at the same time, such as long update cycles, relative high threshold and cost, and inability to dynamically cross multiple knowledge bases.
After summarizing the shortcomings of the fine-tuning and training methods above, KBGPT uses another more common context-based question-and-answer approach. Under this approach, we segment business documents and calculate embedding vectors. When serving customers, we match several groups of business documents with the highest relevance to the embedding vectors of the question and then apply prepared prompt word templates. The template strictly limits and controls the answers, thereby achieving precise and controllable results. As for use, business personnel only need to write business documents and submit them to the system, which will automatically complete the relevant processing. In testing, LLM was well limited by the prompts’ context rules (see Section 2.3) to narrow down the range. At the same time, in topic testing, if the question only involves one topic, this method can concentrate answers within that topic. If the question involves multiple topics, the system will automatically match multiple topics and submit them to LLM for a comprehensive response. If the question does not involve any business themes, a negative answer is given directly.
To further optimize the customer experience, we found that in practical experience, most users will ask the same questions. Based on this characteristic, the system will cache questions and answers and match them with similar questions asked later. This method utilizes existing computational results and has a faster response time. Each time the knowledge base is updated, the system will batch-refresh the existing cache question library based on the new knowledge.
KBGPT uses Sanic Web servers to encapsulate the above business logic into Rest API interfaces, and deploys clusters together with Redis databases using Docker containerization technology. At the interface level, high concurrency and parallelism are achieved through Python’s asynchronous features. The system also uses SSE (Server-Side Event) features of the HTTP protocol to provide streaming interfaces.
KBGPT has the following functional characteristics:
● Provides question-and-answer services through Rest API interfaces, supporting one-time and SSE-streaming responses.
● Adds caching mechanisms to interfaces to quickly return similar answers to matching questions.
● Provides a knowledge base refresh interface through Rest API interfaces. Business personnel can upload business documents in batches, and the system will automatically complete document segmentation, embedding calculation, vector storage, and cache refreshing processing.
● The system provides high-concurrency features through Python’s async functions. Multiple subprocesses are configured in the Sanic server to achieve true parallelism.
2. Context-based question answering system.
KBGPT is a question-answering system that is based on knowledge context. The system divides business documents into segments, and calculates text embeddings to obtain knowledge by utilizing the text similarity search function provided by Redis and RediSearch. KBGPT packages acquired knowledge into contexts, filling them into prompt word templates based on “Zero Shot” and “Chain of Thought”, then invokes LLM to generate responses. The service provided by KBGPT utilizes Python’s asynchronous features and Sanic server for parallelism and high-concurrency.
2.1 Text Similarity
Text embedding is the representation of text in a high-dimensional space. KBGPT uses industry-leading vector storage Redis and RediSearch to calculate text similarity. The cosine distance cos(θ) is calculated as shown in Formula (1), where A and B are two vectors with the inner angle θ. Text embedding is based on frequency counting, and each component of the vector is greater than 0. Therefore, 0<= 1 - cos(θ)<=1, similarity increases from 1 to 0, where 1 indicates completely unrelated and 0 indicates exactly the same.
similarity= 1-cos(θ) =1-A∙BAB
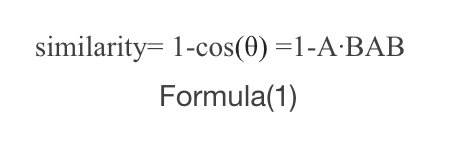
2.2 Q&A Workflow
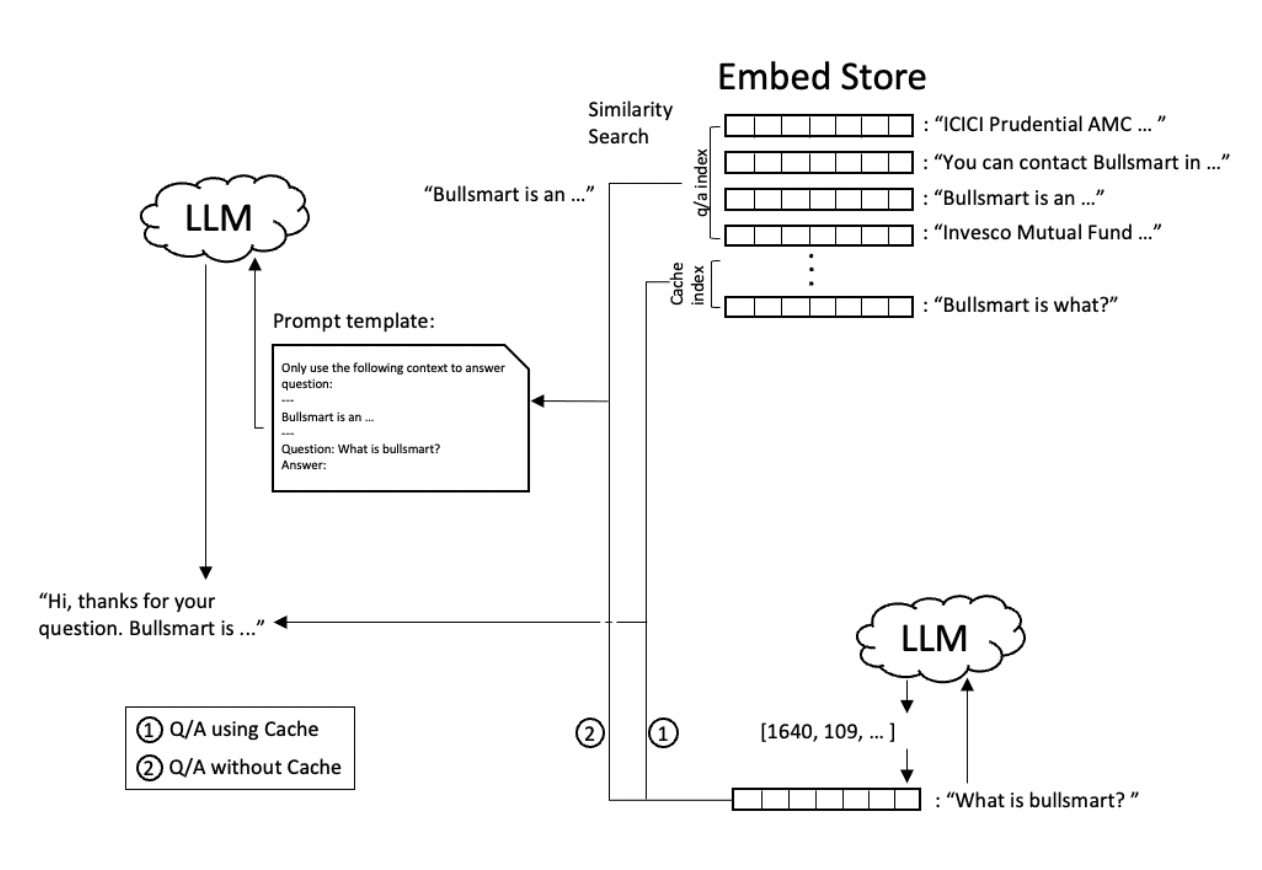
Text embedding plays a critical role in similarity calculation. Currently, most LLMs provide the functionality of generating text embeddings. In the Q&A process, KBGPT first submits the question to the LLM to calculate the text embedding and obtain an N-length embedding vector. N is a hyperparameter determined during LLM training, whose size varies depending on the model, such as ChatGPT’s embedding length of 1536.
Next, KBGPT uses text embedding as a parameter to call RediSearch’s KNN similarity search to retrieve highly similar text, as shown in branch in Figure (1), where a Q/A index is used. RediSearch will select the top k documents with the highest similarity. To control costs while ensuring content diversity, k is generally set between 3 and 5, and only one document is taken in this example. The document is packaged into context and sent to the LLM along with the question, using a prompt template. There is no threshold set for similarity here, and the reason will be discussed in Section 2.3 Prompt Template.
In practice, the vast majority of questions are relatively similar. Before querying the Q/A index, KBGPT queries and returns results from the cache index, which is queried in a similar way to the text query. However, unlike regular queries, the cache has a higher requirement for question similarity, with threshold values generally set between 0.01 and 0.05. The process is shown in branch of Figure (1). Cache matching can be seen as a deduplication problem, and there are specialized solutions in the industry that use Siamese neural networks for deduplication, which will be discussed in Section 3.1.
2.3 Prompt Template
Prompt engineering play a critical role in LLM invocation, as excellent prompts can more effectively utilize the emerging power of large language models. Currently, many new techniques have surfaced in this field, some of which are Zero Shot, Few Shot, Chain-of-Thought, and ReAct, that are quite relevant.
Zero Shot provides a direct description of the problem. Few Shots offers examples of answers along with the problem to enable the model to imitate the response. Chain-of-thought instructs the model to reason step by step based on the previous steps’ outcomes until it reaches an answer. ReAct adopts a cyclic model of reasoning and action (Reason+Action), with external operations integrated into its Action segment. Through experimentation and testing, we have found that a combination of Zero Shot and Chain-of-Thought can adequately satisfy our Q&A requirements.
Figure 2 depicts an example of a prompt, where the prompt begins with role substitution to help the LLM recognize the intended task . This is followed by knowledge context containing information relevant to the problem . Next comes the rule list, wherein only the contents of the context relevant to the question are allowed, emphasizing the use of solely question-related context content . The prompt also includes guidelines for handling cases when the question cannot be answered .

This prompt has already reached the upper limit of complexity for a single problem. A more sophisticated design is required to accomplish more intricate tasks, as outlined in section 3.2.
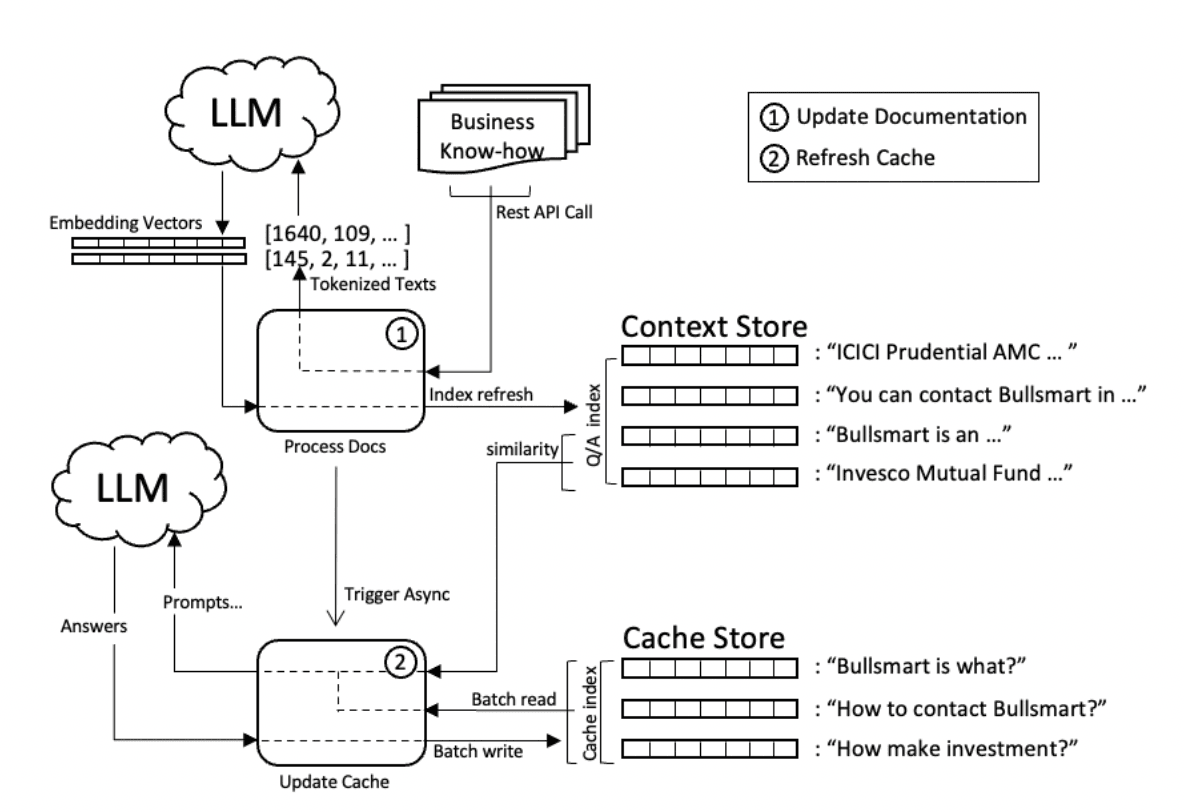
2.5 Cache Refresh
The introduction of caching has improved the efficiency of question and answer systems, but it also results in dirty cache issues. In Redis cache of KBGPT, differences exist between knowledge contents when updated in knowledge context. At this point, KBGPT initiates an asynchronous task to refresh the cache. This task re-queries the context, creates prompts, calls LLM and updates the cache for each question in the cache. To improve efficiency, the asynchronous task will process the questions in batches and in parallel.
The business document is chunked, token computation and embedding vectors are calculated, and then saved to Redis vector storage database as shown in Process in Figure (3), making the entire process an atomic operation. Before the end of this process, the cache process for question and answer (Process in Figure (1)) will be suspended to prevent reading dirty cache and then asynchronously trigger the cache refresh task. This task will read all cached questions in batches, re-match related contexts, submit question requests and update the cache, as shown in Process .
2.6 Service and Deployment
During peak periods of service, KBGPT may need to handle tens of thousands of requests at the same time, which puts strict requirements on high availability, high concurrency, and throughput of the service. The new feature async function in Python language provides coroutines and event queues to prevent threads from being blocked under I/O situations. Coroutines are more lightweight and provide higher concurrency than multithreading. KBGPT uses Sanic server, configured with multiple service subprocesses, overcoming the problem of Python language’s Global Interpreter Lock (GIL) and achieving true parallel processing of requests.
In terms of deployment, OPS adopts the method of establishing its own Redis service, allowing KBGPT and Redis to be deployed nearby, thereby improving context access efficiency. At the same time, the configured persistence and high availability make the service more reliable.
3. Future Work
This section discusses relevant issues encountered during the construction of KBGPT, such as problem similarity and prompt engineering, and provides feasible solutions. This section also provides solutions based on the company’s overall deployment of AIGC.
3.1 Model-based Text Similarity
The underlying principle of text similarity in Section 2.1 of this article is based on the probability of word occurrence, which is limited in understanding synonymous or conceptual problems. For example, for two questions like “What is your age?” and “How old are you?”, similarity algorithms based on text embedding cannot determine that they are the same question. Classic solutions include Siamese Network used in questioning platforms such as Quora or StackOverflow. Currently, open source question similarity models on Huggingface, such as sentence-transformers/all-MiniLM-L6-v2, offer more control than single similarity methods, but require deploying related models privately.
3.2 Prompt Word Engine
As a tool for calling LLM, prompt words play a crucial role in the age of LLM. LLM is not a magic lamp like Aladdin’s, but rather, in practice, we find that the accuracy and diversity of prompt words seem to be two sides of the same coin and are difficult to balance. In a prompt word, the more vague the question, the less precise the result, but the response can be rich and interesting. Moreover, LLM cannot understand the priority and implicit meaning of complex instructions well. For example, if you want LLM to read a piece of content and then choose a way to respond with different probabilities (1:4:5) for each option below:
- Express gratitude and wrap all responses in 3-4 emojis, such as 🙏🙏🙏🙏Thanks!🙏🙏🙏🙏🙏.
- Provide an in-depth analysis.
- Find meaningful content not mentioned in the reading material and ask questions.
In this case, LLM can understand the content of the reading material well, but it is difficult to achieve the desired results when selecting output styles. The main problems are format issues, such as adding selected options to the output and counting how many emojis have been added; content issues, such as carrying the format of Option 1 to Option 2 and Option 2 beginning to ramble on; and logical problems, such as being unable to generate results accurately according to probability. In this case, modifying the prompt word may make the originally complex logic even more confusing.
Therefore, we can design prompt word templates according to scenarios, and generate prompt words based on random or selection parameters to make them more controllable. In certain situations, the engine can also call external data, such as market trends, as illustrated in Figure(4).
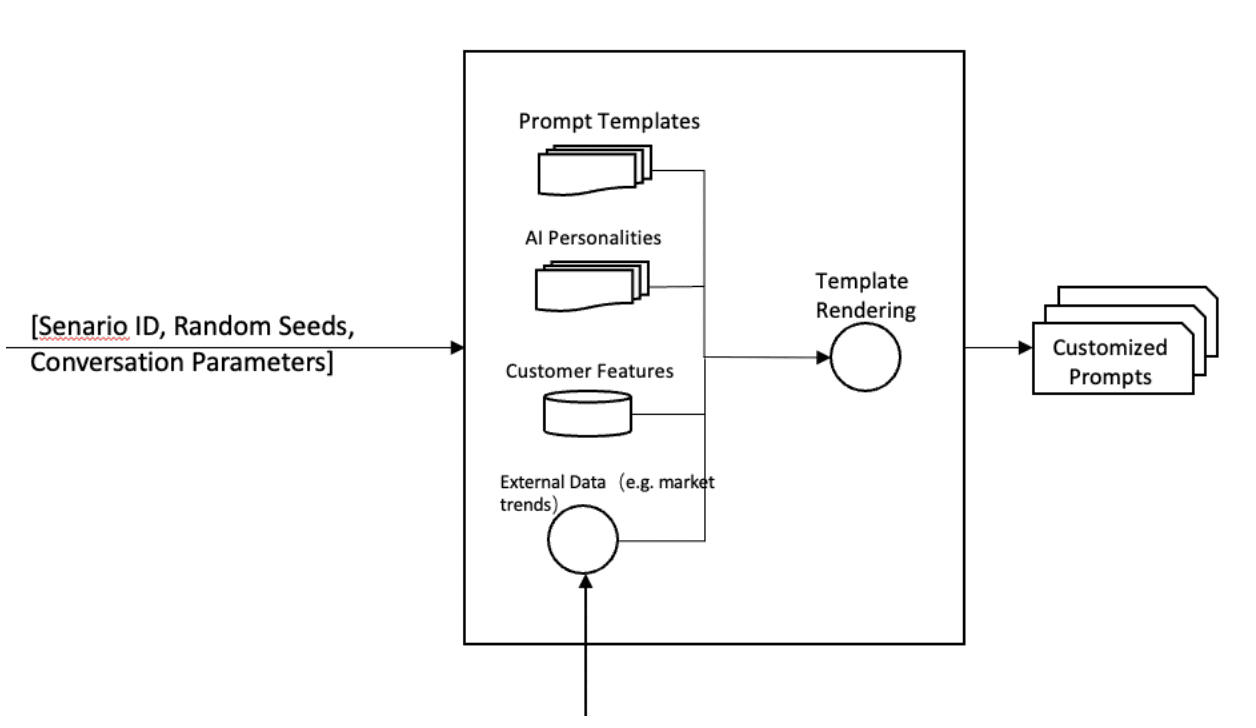
Regarding the example mentioned above of wrapping text with emojis, we can add relevant Few-Shot prompt word fragments to the AI virtual personality library, such as:
Your reply should be wrapped by Emojis. here are some examples:
- 🙏🙏🙏🙏thanks🙏🙏🙏🙏
- 😄😄😄😄hahaha😄😄😄.
This fragment is embedded into the prompt word during template rendering, and the rendered result will only contain this one way of responding. By adding random parameters during generation and using this personality library, prompt words can be constructed in a more diverse, random, and controllable manner. For example, when a recommendation-style response needs to be given based on the user’s own situation, user feature data can be obtained and rendered into the prompt word template. These combined with the use of the AI virtual personality library can achieve customized customer service. From a higher perspective, this engine can be uniformly integrated into all generative interfaces to provide rich content support for diverse scenario capabilities.
3.3 AIGC Architecture
This section takes an opportunity to design a preliminary AIGC framework based on context-based question-answering systems. This framework relies on the inference support provided by large models to provide services for scenario needs. Our company’s business is flexible and diverse, and is developing rapidly. A single, fixed framework cannot meet the requirements of its flexibility. How to use existing computing resources and AI resources to support scenario calls is the main issue that this framework needs to solve, as shown in Figure (5).
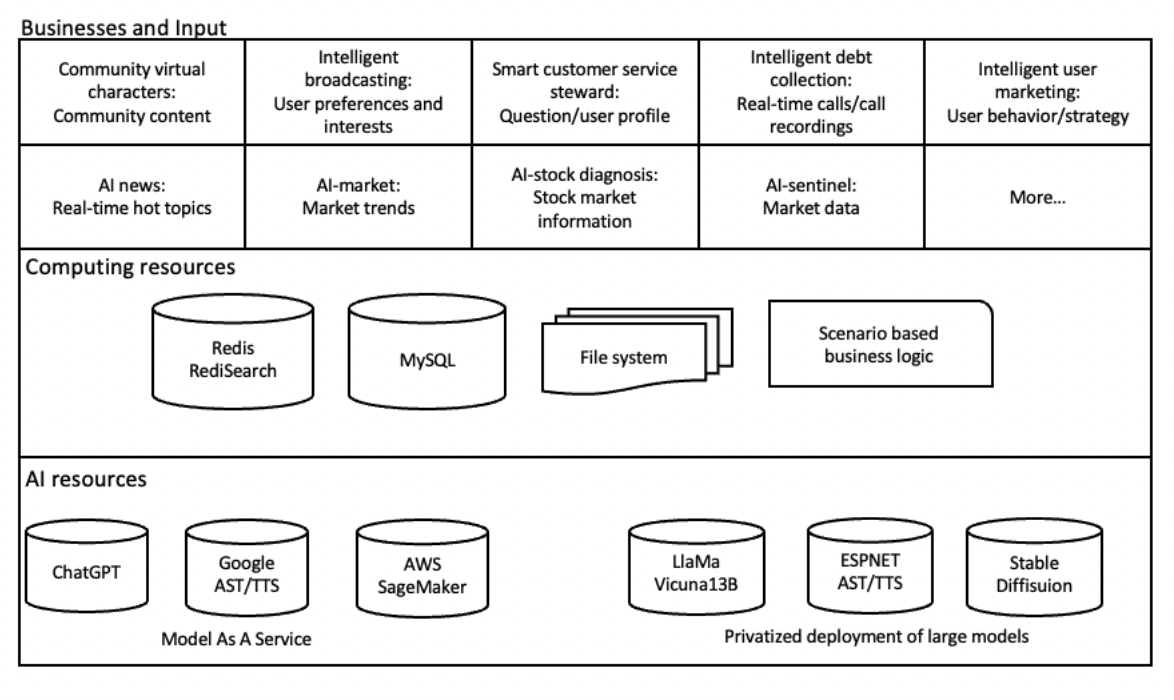
In order to adapt to flexible and changing scenario needs, this framework adopts a way of generating business logic based on configuration, and through a carefully designed internal interface, makes data, text, images, and multimedia compatible into a process pipeline. Based on the configured generated business logic, it can be directly integrated into the graphical user interface, and users can generate business logic through interaction with controls. This also enables business personnel to generate the content they want directly according to their business needs.
The AIGC framework mainly consists of a graphical user interface, Manufacture Engine, Invocation Library, Process Library, and Result Library. Among them, the graphical user interface and manufacturing engine belong to the definition side of the framework, while the invocation library, process library and result library belong to the functional side of the framework. This architecture uses the structured language JSON declaratively to define the AIGC business pipeline. As shown in Figure (6), based on text generation, a Q&A-style response with text, voices and images can be quickly constructed by defining input, process, and corresponding results. For complex applications, business pipelines can define concatenation, conditional, or parallelism by connecting the invocation to another pipeline’s result to meet more flexible and changing scenario AIGC needs.
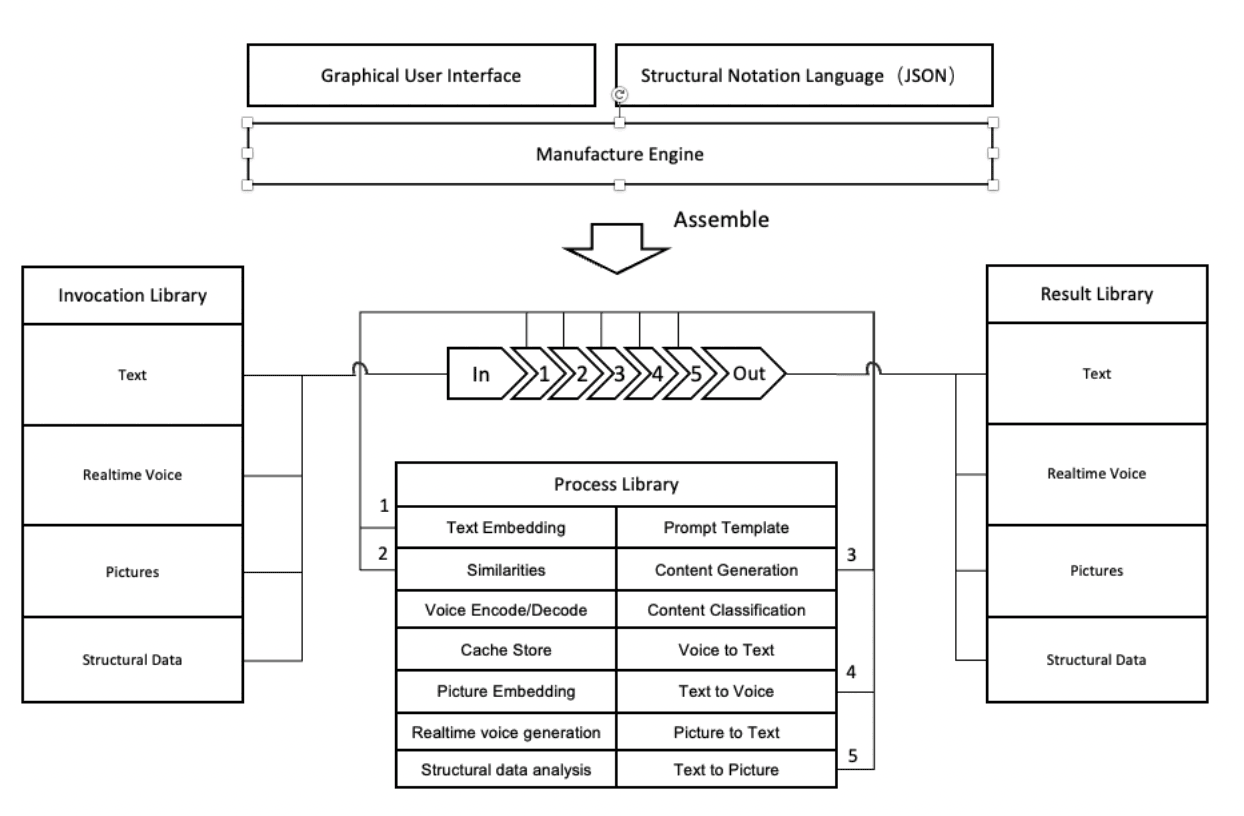
The assembled pipeline is divided into input, processing steps 1-5, and output steps. The input has a clearly defined format, size, and length information; the steps have various parameters including large model types, addresses, vector storage addresses, etc. Likewise, the output defines the format of the output and the method of returning the call.
The implementation of this architecture involves multiple critical technologies, which will be briefly described due to limited space here. First is the description and transformation of data structures in different forms in the pipeline. There must be a unified interface between the calling, processing, and results steps. Mapping of each process during parsing and assembly, as well as automatic and parameterized configuration processes, etc.
4. Acknowledgements
This article was written in a hurry, and readers are invited to criticize and correct any errors found throughout. The main purpose of this article is to inspire greater attention and creativity within the company towards the current AI trend, as well as encourage colleagues and partners to join in on AI-related applications and development.
Finally, during the ideation and writing stages of this article, it received great help and support from leaders and colleagues alike. While I cannot list them all, the most deserving of thanks include: my supervisor, for their criticism and guidance; the ChatGPT project team; and the strong support of the Bullsmart development team and OPS. Thank you again!