


A good number of people first learn about databases as relational databases, where data is stored in tables, with one row representing one record. In fact, this is a typical Row-based store, which stores tables on disk partitions by rows.
And some databases also support Column-based store, which stores tables on disk partitions by column.
Comparison of storage methods
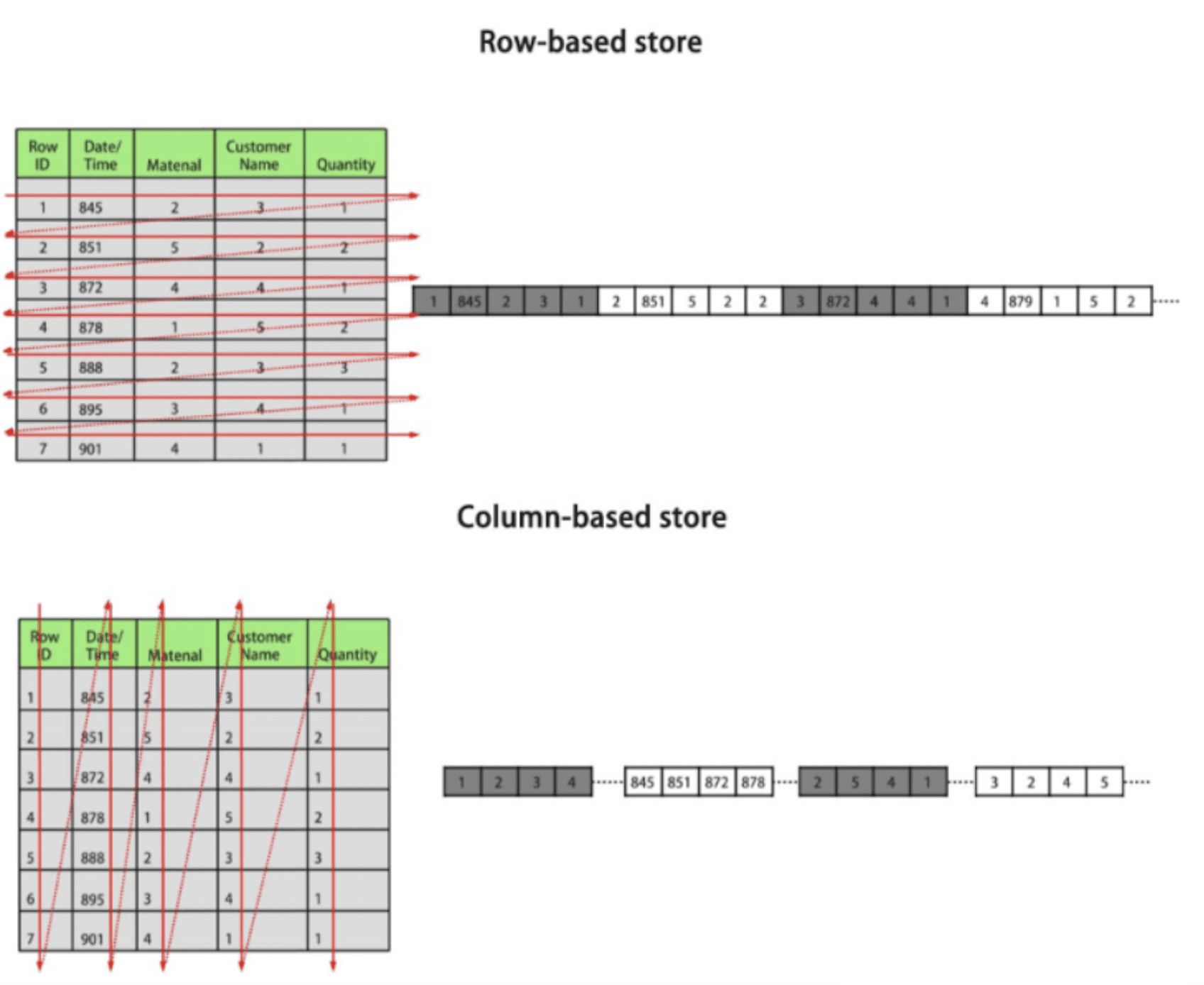
As you can see from the figure, in row storage, the attribute value of a row is stored in the adjacent space, followed by the attribute value of the next record.
In the case of column storage, all the values of a single attribute are stored in the adjacent space, i.e., all the data of a column are stored consecutively, and each attribute has a different space.
Here, you can think about the two kinds of more suitable for querying, and more suitable for modifying?
1) Writes to row storage are done in a single pass. Writes are built on the operating system's file system, which guarantees the success or failure of the writing process, so the integrity of the data can be determined.
(2) Columnar storage requires splitting a row of records into a single column, so the number of writes is significantly higher than row storage, and the actual time consumption is greater because of the time required to move and position the head on the disk. Therefore, row storage has a great advantage in writing.
3) There is also data modification, which is actually a write process. So, data modification is also dominated by line storage.
(1) Row storage usually takes out a row of data completely, and if only a few columns of data are needed, there will be redundant columns, and the process of eliminating redundant columns is usually done in memory for the sake of shortening processing time.
2) Column storage reads a section or all of the data of a collection each time, there is no redundancy problem, and the lookup content is stored continuously, which is especially suitable for projection.
3) Data distribution for both stores. Since each column data type of column storage is homogeneous, there is no problem of duality. For example, if the data type of a column is integer (int), then its data set must be integer data. This situation makes data parsing very easy. In contrast, row storage is much more complex, because multiple types of data are stored in a row, and data parsing requires frequent conversions between multiple data types, which consumes CPU and increases the parsing time. Therefore, the parsing process of column storage is more conducive to analyzing big data.
4) Comparison in terms of data compression and more performance reading. The same column of data, the same data type, column storage mode is suitable for data compression, different columns can use different compression algorithms, compressed storage will bring IO performance improvement.
Comparison of advantages and disadvantages
|
|
Row Storage | Column storage |
| Advantages |
Data is saved together. inserts/updates easily. |
|
|
Disadvantages |
When Selection, all data is read even if only a few columns are involved. |
|
|
Applicable scenarios |
1.Point query (return few records, simp
le query based on index).
2. Scenarios with more additions, deletions and changes. |
1.Statistical analysis type of query (OLAP, such as data warehouse business, this type of table will do a lot of convergence calculations, and involves fewer column operations, more correlation, grouping operations).
2.Instant query (query conditions are uncertain, row storage table scan is difficult to use indexes) |
Row and column storage experiments
openGauss supports mixed storage of rows and columns, and you can specify the storage method when you build a table. Let's conduct the following experiments.
Experimental environment: Huawei Cloud Server + openGauss Enterprise Edition 3.0.0 + openEuler20.03
Create a row storage table custom1 and a column storage table custom2 and insert 500,000 records.
openGauss=# create table custom1 (id integer,name varchar2(20));CREATE TABLEopenGauss=# create table custom2 (id integer,name varchar2(20)) with (orientation = column);CREATE TABLEopenGauss=# insert into custom1 select n,'testtt'||n from generate_series(1,500000) n;INSERT 0 500000openGauss=# insert into custom2 select * from custom1;INSERT 0 500000
openGauss=# \d+List of relationsSchema | Name | Type | Owner | Size | Storage | Description--------+------------+-------+-------+------------+--------------------------------------+-------------public | custom1 | table | omm | 24 MB | {orientation=row,compression=no} |public | custom2 | table | omm | 3104 kB | {orientation=column,compression=low} |
openGauss=# explain analyze insert into custom1 values(1,'zhang3');QUERY PLAN-----------------------------------------------------------------------------------------------[Bypass]Insert on custom1 (cost=0.00..0.01 rows=1 width=0) (actual time=0.059..0.060 rows=1 loops=1)-> Result (cost=0.00..0.01 rows=1 width=0) (actual time=0.001..0.001 rows=1 loops=1)Total runtime: 0.135 ms(4 rows)openGauss=# explain analyze insert into custom2 values(1,'zhang3');QUERY PLAN-----------------------------------------------------------------------------------------------Insert on custom2 (cost=0.00..0.01 rows=1 width=0) (actual time=0.119..0.120 rows=1 loops=1)-> Result (cost=0.00..0.01 rows=1 width=0) (actual time=0.001..0.002 rows=1 loops=1)Total runtime: 0.207 ms(3 rows)
Finally, delete the test table.
openGauss=# drop table custom1;DROP TABLEopenGauss=#drop table custom2;DROP TABLE
Selection advice
-
Update frequency: If the data is updated frequently, select the row storage table.
-
Insertion frequency: For frequent insertion of small amount, select row storage table. If you insert a large amount of data at a time, select the column storage table.
-
The number of columns in the table: In general, if the table has more fields, that is, the number of columns (large wide table), the query does not involve many columns, suitable for column storage. If the number of fields in the table is relatively small and most of the fields in the query, then it is better to choose row storage.
-
The number of columns in the query: If each query involves only a few (<50% of the total number of columns) columns of the table, choose column storage table. (Don't ask what the rest of the columns are for, A says useful is useful.)
-
Compression rate: column storage table than row storage table compression rate is high. But the high compression rate will consume more CPU resources.