


1.Bloom filter
Bloom filter is a space-saving probabilistic data structure for testing whether an element is a member of a collection or not. It is used in scenarios where we only need to check if an element belongs to an object.
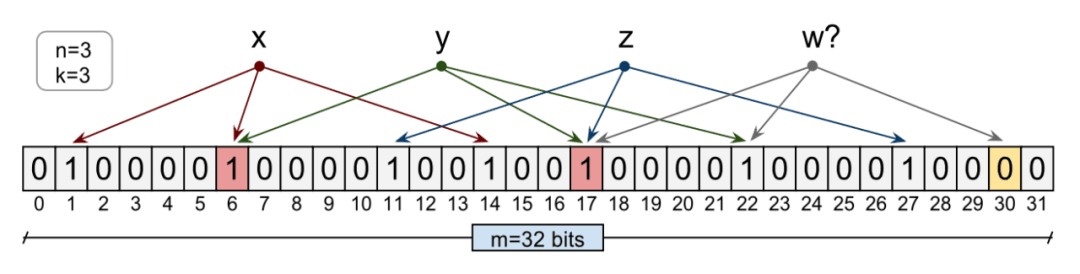
In BigTable (and Cassandra), any read operation must read from the SSTables that make up the Tablet. To reduce the number of disk accesses, BigTable uses Bloom filters.
2.Consistency hash
Consistent hashing allows you to easily scale, thus allowing data to be replicated in an efficient manner, resulting in better availability and fault tolerance.
Each data item identified by a key is assigned to a node by hashing the key of the data item to produce its position on the ring, and then traversing the ring clockwise to find the first node with a position greater than that position. The node associated with the node is the location of the data item.
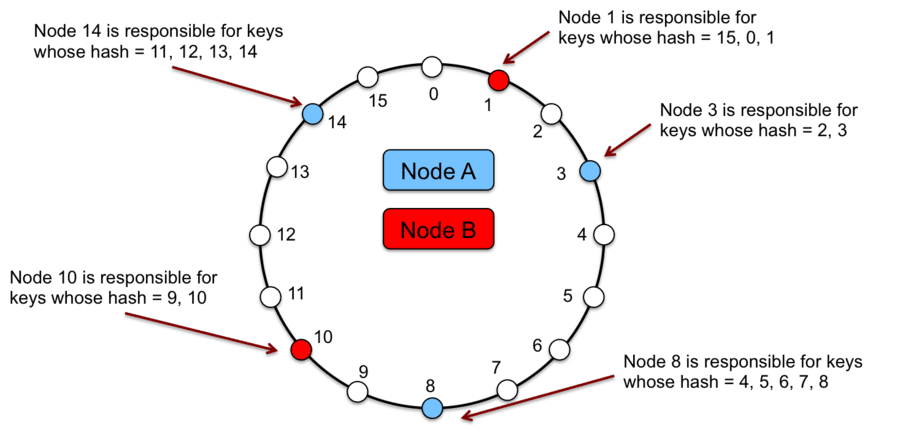
The main advantage of consistent hashing is incremental stability; the departure or arrival of a node to a cluster affects only its immediate neighbors, other nodes are not affected.
3.Quorum
In a distributed environment, quorum is the minimum number of servers that need to successfully execute this distributed operation before the operation can be confirmed as successful.
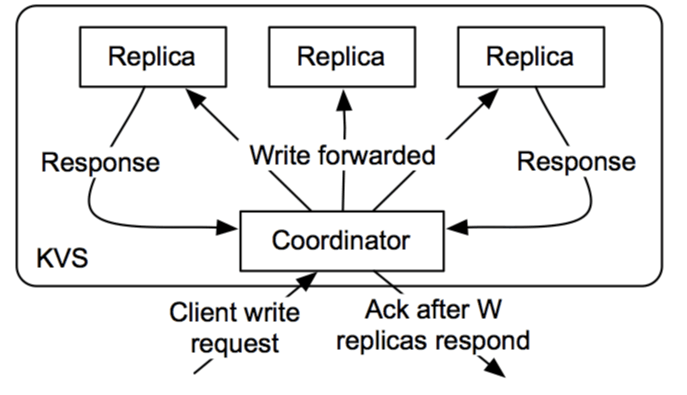
Cassandra, to ensure data consistency, each write request can be configured to succeed only if the data has been written to at least one quorum (or most) replica nodes.
For leader elections, Chubby uses Paxos, which uses quorum to ensure strong consistency.
4.Leader (Leader) and followers (Follower)
In order to achieve fault tolerance in systems that manage data, it is necessary to replicate data across multiple servers.
One server is selected as the leader in the cluster. The leader is responsible for making decisions on behalf of the entire cluster and propagating them to all other servers.
The heartbeat mechanism is used to detect if an existing leader has failed so that a new leader election can be initiated.
6.Fencing
In the leader-follower model, it is not possible to determine that a leader has stopped working when the leader fails. For example, a slow network or network partition may trigger a new leader election even though the previous leader is still running and considers it still the active leader.
Masking is the process of placing a fence around a previously active leader so that it cannot access cluster resources, thereby stopping service for any read/write requests.
The following two techniques are used.
-
Resource blocking: The system blocks previously active leaders from accessing resources needed to perform basic tasks.
-
Node Masking: The system blocks previously active leaders from accessing all resources. A common way to perform this action is to power off or reset the node.
7. WAL (pre-written log Write-ahead Log)
Pre-written logging is an advanced solution to the problem of file system inconsistencies in operating systems. Inspired by database management systems, this method first writes a summary of the operations to be performed into a "log" and then physically writes them to disk. In case of a crash, the operating system simply checks this log and continues from the point of interruption.
8.Segmented log
Split logs into multiple smaller files rather than a single large file for ease of operation.
Individual log files can grow and become a performance bottleneck when read at startup. Older logs are purged periodically and it is difficult to perform purge operations on a single large file.
9. High-Water mark
The last log entry on the leader that has been successfully copied to the follower's quorum. the index of this entry in the log is called the high-water trail lead. The leader only exposes data to the high water trail lead.
10, Lease
A lease is like a lock, but it works even if the client leaves. The client requests a lease for a limited period, after which the lease expires. If the client wants to extend the lease, it can renew the lease before it expires.
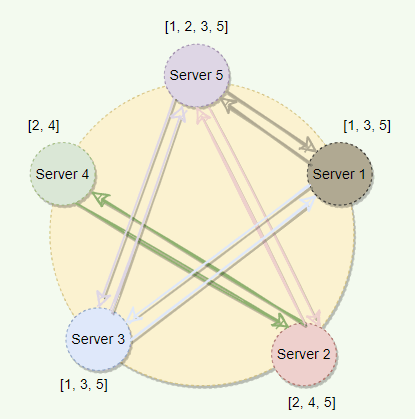
11. Gossip protocol
The Gossip protocol is a peer-to-peer communication mechanism in which nodes periodically exchange state information about themselves and other nodes that they know about.
Each node initiates one Gossip round per second to exchange state information about itself and other nodes with another random node.
This algorithm uses historical detection signal information to make the threshold adaptive. A generic accrual fault detector does not determine whether a server is active or not, but instead outputs the suspicious level of the server in question.
13.Brain fracture
A scenario in which a distributed system has two or more active leaders is called a brain fracture.
The brain fracture problem can be solved by using a Generation Clock, which is simply a monotonically increasing number that indicates the generation of servers.
Each time a new leader is elected, the generation number is increased. This means that if the old leader had a clock number of "1", the new leader will have a clock number of "2". This clock number is included in every request sent from the leader to the other nodes. In this way, nodes can now easily distinguish the true leader by simply trusting the leader with the highest number.
Kafka: To handle brain fractures (we can have multiple active controller brokers), Kafka uses the "Epoch number", which is simply a monotonically increasing number to represent the generation of the server.
14. checksum
In a distributed system, data obtained from nodes may be corrupted when moving data between components.
Calculate the checksum and store it with the data.
To calculate the checksum, use a cryptographic hash function such as MD5, SHA-1, SHA-256, or SHA-512. The hash function takes the input data and generates a fixed-length string (containing letters and numbers); this string is called the checksum.
When the system stores some data, it calculates the checksum of the data and stores the checksum with the data. When the client retrieves the data, it verifies that the data received from the server matches the stored checksum. If not, then the client can choose to retrieve that data from another copy.
The CAP theorem states that a distributed system cannot simultaneously provide all three of the following desirable properties.
Consistency (C), Availability (A), and Partitioning Tolerance (P).
According to the CAP theorem, any distributed system needs to choose two of the three properties. These three options are CA, CP, and AP.
Dynamo: In CAP theorem terminology, Dynamo belongs to the class of AP systems designed to achieve high availability at the expense of strong consistency.
The PACELC theorem states that in a system of replicated data.
-
If there is a partition ('P'), the distributed system can make a tradeoff between availability and consistency (i.e., 'A' and 'C');
-
Otherwise ('E'), the system can trade-off between latency ('L') and consistency ('C') when the system operates normally without partitioning.
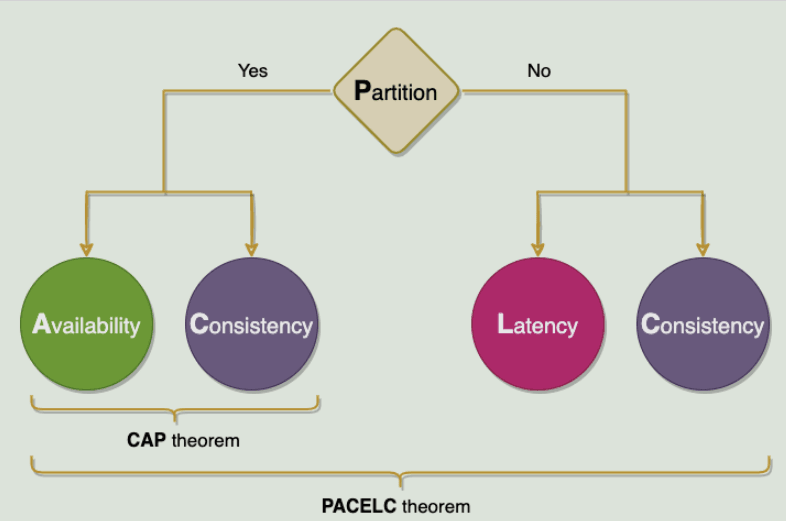
The first part of the theorem (PAC) is the same as the CAP theorem, and the ELC is the extension. The whole argument assumes that we maintain high availability through replication. Thus, when it fails, the CAP theorem prevails. But if not, we must still consider the tradeoff between consistency and latency of the replicated system.
17.Hinted Handoff
If a node shuts down, the system keeps hints (or comments) of all the requests they missed. When the failed node recovers, requests will be forwarded to them based on the stored hints.
In a distributed system where data is replicated across multiple nodes, some nodes may end up with outdated data.
The obsolete data is repaired during the read operation, because at this point, we can read data from multiple nodes to compare and find the node with the obsolete data. This mechanism is called read repair. Once the node with the old data is known, the read repair operation pushes the newer version of the data to the node with the older version.
"Read Repair eliminates conflicts while the read request is being processed. However, if a replica is significantly behind other replicas, it may take a long time to resolve the conflict.
Replicas can contain large amounts of data. Simply splitting the entire range to compute checksums for comparison is not very feasible; there is too much data to transfer. Instead, we can use a Merkle tree to compare copies of a range.
Merkle trees are hashed binary trees, where each internal node is a hash of its two children, and each leaf node is a hash of a portion of the original data.
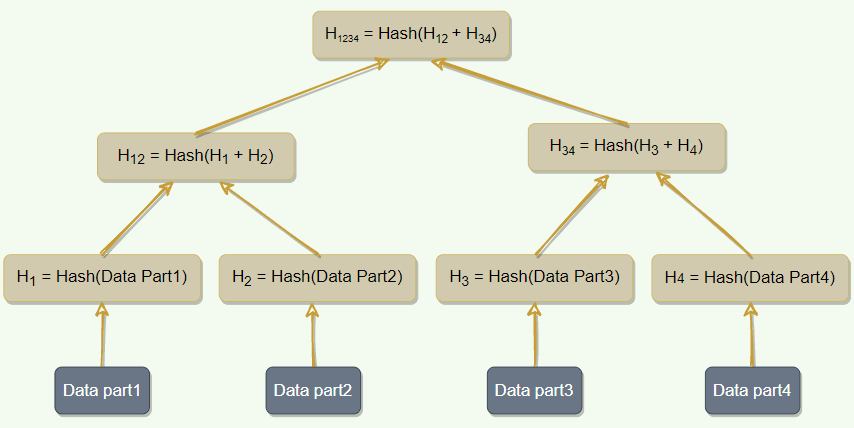
-
Compare the root hash of two trees.
-
If they are equal, stop.
-
Check recursively on the left and right children.
To implement anti-entropy and resolve conflicts in the background, Dynamo uses Merkle trees.