-
Limitations of traditional thinking
-
How does the CDN work?
-
The magical interpretation rights mechanism (SOA)
-
The basic principles of DNS load balancing
-
Summary
When the site is visited by a large number of people will consider load balancing, which is the basic skills of every architect, its basic status is equivalent to the comedy of learning and singing, live or not on this :)
The traditional load balancing idea is a single point of view, whether you are a hardware or software is basically the principle, as shown in the following figure.
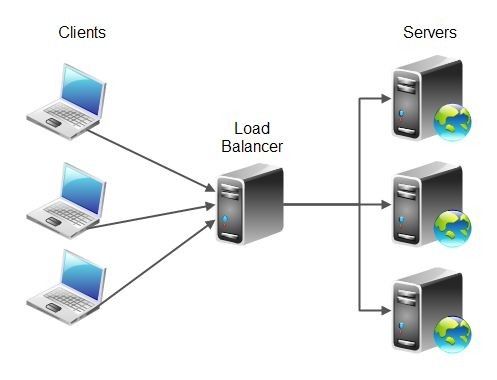
For general requirements, such an architecture basically solves the problem and is relatively easy to maintain, and most companies do it that way.
Limitations of traditional thinking
As the above diagram shows, there are very obvious limitations to the traditional thinking.
That is, the response speed of the website is largely limited to the capacity of the load balancing nodes, and once the load balancing node itself hangs, the whole website is completely paralyzed.
The back-end service can be scaled horizontally, but for a single node even if you increase the machine configuration again, there is a limit, and this is not in line with the development of the Internet technology law.
How CDNs are made
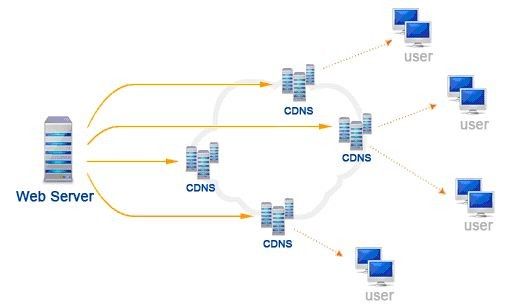
As a major infrastructure that carries most of the traffic on the Internet, CDN's solution to load shunting is an inspiring idea, as follows.
As you can see from the figure above, user access is triaged, and all requests are no longer aggregated to one node, but are shared among the appropriate nodes.
This way, even if there is a single point of failure, it only affects a portion of users, and we can use other means to do failover.
The same approach can be applied to the traditional BS architecture, where we can also divert user requests directly to different servers instead of going through a single node.
What is this triage done by?
Do you know how DNS works?
Most people may use DNS every day but do not know its basic principles, you may know that we need to access the Internet to query the dns server.
All we need to do is ask for the ip address corresponding to its domain name.
But is it really that simple? How does it know the IP address corresponding to this domain name?
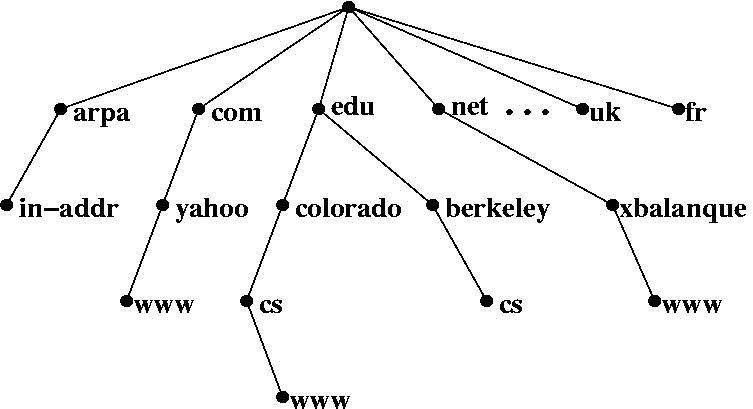
In fact, the dns system is a typical tree architecture. The dns server shown above should actually be called a dns cache query server, which is designed to reduce the load of dns queries on the Internet.
If your request doesn't hit the cache, then this cache server will do a standard query itself and then cache the result, simply put, it starts from the root server at one level.
We used to talk about the importance of the root server is actually reflected here, it retains the right to interpret the beginning of all domains
The magical interpretation rights mechanism (SOA)
It was mentioned above that the root server has the initial interpretation of all domains, but if you ask the root server it won't tell you the final answer directly.
Because if it were to store all the records, it would be too tired, and the load and overhead would be staggering.
So what will it tell you? It will tell you who to ask, that is, it authorizes the next level of server to answer your question.
Let's look at the following anthropomorphic process.
-
Me: root, root tell me, segmentfault.com how to go?
-
root: Oh, you can ask the dns server of .com, the address is xxxxxxx
-
Me: .com, .com tell me, segmentfault.com how to go?
-
.com: Oh, you can ask the dns server of segmentfault.com (dnspod or something like that), the address is xxxxxxx
-
Me: dnspod, dnspod tell me, how to go to segmentfault.com?
-
dnspod: take xxxxxx, go you
The basic principles of DNS load balancing
Understanding the above process, we get two basic conclusions
-
The dns system itself is a distributed network, it is relatively reliable, at least more reliable than your website itself
-
The ultimate interpretation of dns is that it can be controlled by ourselves
With these two conclusions, the rest is easy, we just need to work on the final interpretation of the query results.
Simply put, it is to return all your server addresses, as often as your own needs are formulated, to the user.
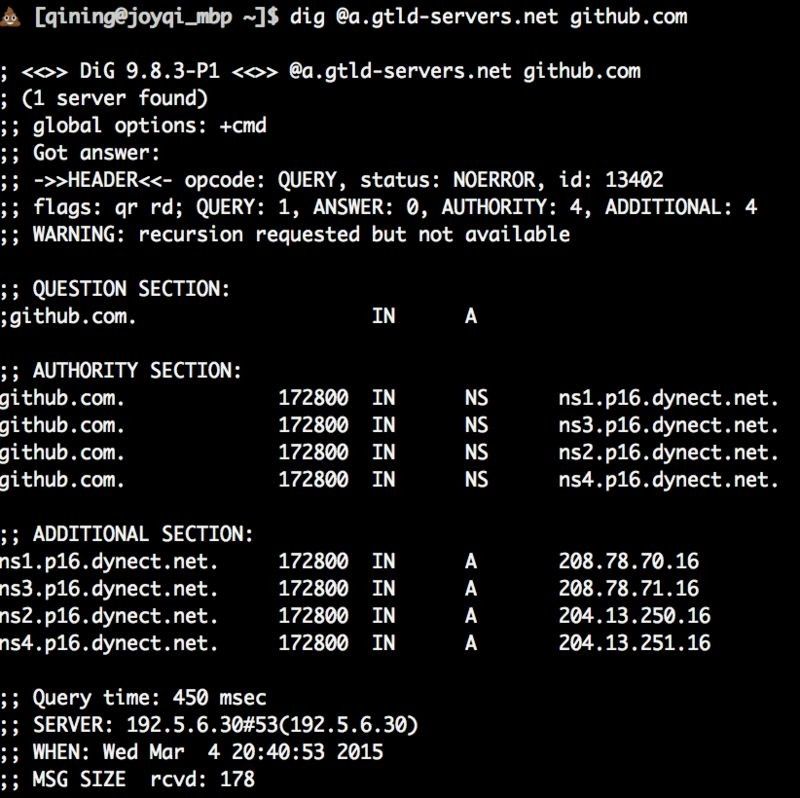
Take github.com as an example, we first get its SOA servers (because the dns cache query server will cache the results, if you go directly to the query domain, it will return the same results every time), .com's dns name servers are also 13, they are [a-m].gtld-servers.net, we randomly choose one to find github.com's SOA. as follows.
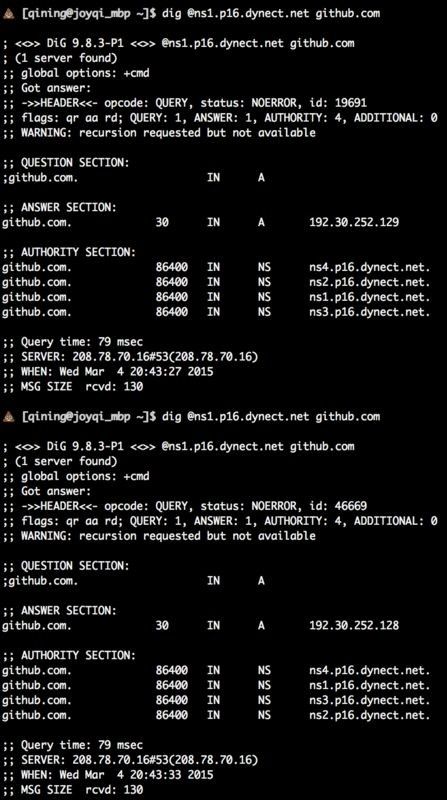
OK, we have obtained four SOA servers ns[1-4].p16.dynect.net, and then choose one at random to ask github.com for the corresponding records, by the way, try a few times to see if the final IP address will change
We query twice here, notice the ANSWER SECTION section returns two results, one for 192.30.252.129 and one for 192.30.252.128.
This is load balancing using dns and your final access will arrive at different ip addresses.
What DNS providers support load balancing?
This is a more advanced service that is not generally supported by the domain registrar's dns servers. The service providers that I currently know support it are
1. AWS Route 53
2. NSONE
3. Dyn
Among them, 1 and 4 are the ones we are already using, and the results are more satisfactory
Summary
In fact, DNS can do much more than that, it can also do failover, it can also resolve by region, and so on.
Domain names have been around since the dawn of the Internet, but the research into it and the methods of use derived from it are only just beginning to be discovered, and as everyone's use of the Internet increases, more and more of these technologies are sure to come.