Recently, I participated in the research and development of a company project and found some minor issues in data management. Based on past experience, I have recorded the microservice data design pattern here.
The services in the microservices architecture are loosely coupled and can be independently developed, deployed, and extended. Each microservice requires different types of data and storage methods, which is why each microservice has its own database.
1.Database for each service
Each microservice has its own database and can freely choose how to manage data.
1.1 The benefits of having a database for each service
- Loose coupling, each service can focus more on their own professional field
- Choose database types freely, such as RDBMS such as MySQL, wide column databases such as Cassandra, document databases such as MongoDB, key value storage such as Redis, and graphic databases such as Neo4J.
Do you need to use a different database server for each service? This is not a mandatory requirement. Let’s see what we can do.
1.2 If you are using RDMS, it includes the following features:
- Dedicated Tables - Each service has a set of tables that can only be accessed by that service.
- Dedicated database architecture - Each service has a private database architecture.
- Dedicated database server - Each service has its own database server.
1.3 The challenge of having a database for each service
Queries that require connecting multiple databases - the following data patterns can overcome this challenge.
event sourcing
API composition
Command Query Responsibility Separation (CQRS)
Cross multiple database transactions - To address this issue, we can use the Saga pattern.
2.Event Sourcing
Through event tracing, the state of a business entity is tracked by a series of events that change state. Whenever the state of a business entity changes, a new event is added to the event list. Since saving an event is a single operation, it is essentially atomic. By replaying events, the application reconstructs the current state of the entity.
The application saves events in the event store, which is the event database. You can use its API to add and retrieve events from storage. The event store also acts as a message broker. Services can subscribe to events through their APIs. When a service saves an event in the event store, it will send it to all interested subscribers. When an entity has a large number of events, the application can regularly save a snapshot of the current state of the entity to optimize loading. The application searches for the most recent snapshot and events that have occurred since that snapshot to rebuild the current state. This reduces the number of events to be replayed.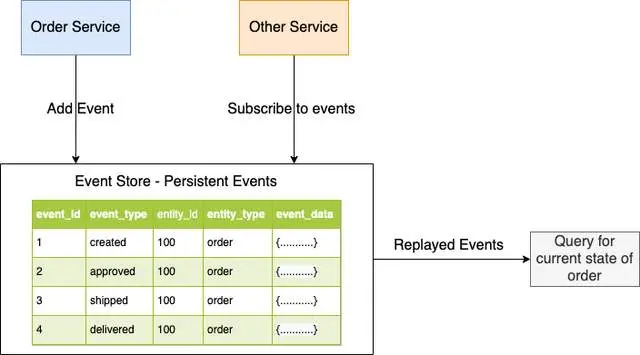
2.1 Benefits of Event Traceability
Using it solves one of the key challenges of event driven architecture and enables reliable release of events when state changes occur.
The problem of impedance mismatch in object relationship is avoided. persistence events are not domain objects.
Provide 100% reliable audit logs for entities.
Allow the execution of time queries to determine the state of an entity at any point in time.
Event tracing based business logic involves loosely coupled entities that exchange events. Making it much easier to migrate from monolithic applications to microservice architectures.
2.2 Disadvantages of Event Traceability
There is a certain learning cost, and currently it is still an immature technology.
Querying event storage is difficult and requires a typical query to reconstruct the entity state. May lead to inefficient and complex queries. Therefore, applications must use Command Query Responsibility Separation (CQRS) to implement queries. On the contrary, this means that the application must process the ultimately consistent data.
3.API composition
You can use the API composite pattern to implement the query operation of retrieving data from multiple services. In this pattern, query operations are implemented by calling services that have data and combining the results.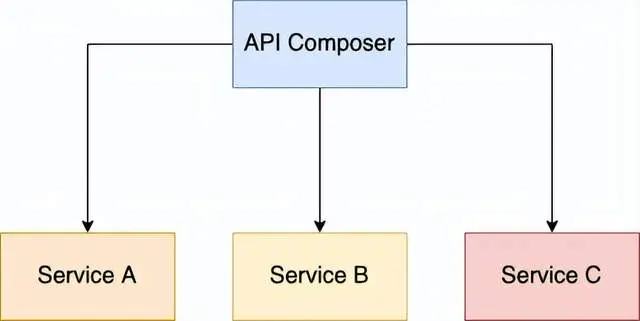
3.1 Benefits of API Combination
A convenient way to query data in microservices architecture.
3.2 Disadvantages of API combination
Sometimes, queries can lead to inefficient memory connections for large datasets.
Command Query Responsibility Separation (CQRS)
RDBMS is typically used as a recording transaction system and text search database, such as Elasticsearch or Solr for text search queries. Some applications maintain database synchronization by writing both simultaneously. Others regularly copy data from RDBMS to text search engines. The application built based on this architecture leverages the advantages of multiple databases, the transaction properties of RDBMS, and the query capabilities of text databases. CQRS summarizes this architecture.
Microservice architecture faces three common challenges when implementing queries.
Use the API composite pattern to retrieve data scattered in multiple services, resulting in costly and inefficient memory connections.
Data is stored in a format or database that does not effectively support queries required by the service that owns the data.
Separating concerns means that services with data should not be responsible for implementing query operations.
These three issues can be solved by using the CQRS mode.
The main goal of CQRS is to separate or separate concerns. Therefore, the persistent data model is divided into two parts: the command side and the query side.
The creation, update, and deletion operations are implemented by command side modules and data models. The query is implemented by the query module and data model. By subscribing to events published on the command line, the query side keeps its data model synchronized with the command side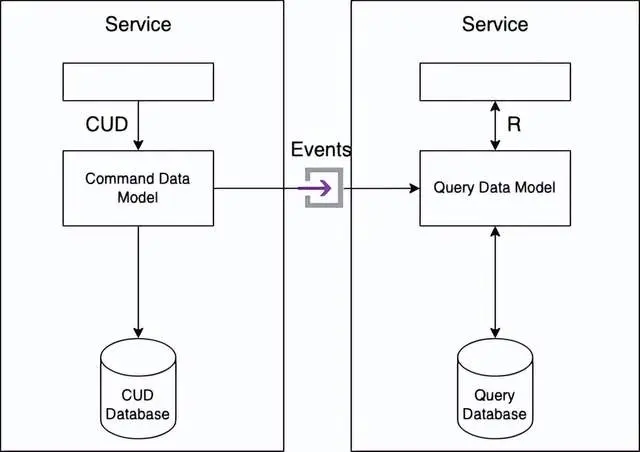
4.1 The Benefits of CQRS
Efficient query implementation - If you use the API composite pattern to implement queries, you may encounter high cost and inefficient memory connections for large datasets. For these queries, using CQRS views that pre connect two or more service data is more effective.
Effectively implementing multiple queries - it is often difficult to use a single persistent data model to support all queries. In CQRS, defining one or more views effectively implements specific queries, eliminating the limitations of individual data storage.
Implementing queries in event tracing based applications - CQRS also overcomes an important limitation of event tracing. Event storage only supports queries based on primary keys. The CQRS pattern addresses this limitation by defining one or more aggregated views that are kept up-to-date by subscribing to event streams published by event source aggregation.
Separation of concerns improvement - domain models and persistent data models do not support commands and queries. CQRS separates the command and query ends of the service into separate code modules and database schemas.
4.2 Disadvantages of CQRS
More complex architecture - In order to update and query views, developers need to write query side services. Applications may use different types of databases, which increases the complexity for developers and DevOps.
Handling replication latency - There is a delay between publishing events from the command side and processing events and updating views from the query side.
5. Saga mode
With sagas, you can maintain the consistency of data in the microservice architecture without using Distributed transaction. You define a saga for each command that updates data across multiple services. Saga is a series of local transactions. Local transactions use the ACID transaction framework to update data in a single service.
Sagas utilizes compensation transactions to roll back changes. Assuming the nth transaction of saga fails. The first (n-1) transactions must be undone. As a result, a total of (n-1) compensation transactions will be initiated to roll back changes in reverse order.
5.1 Saga Coordination
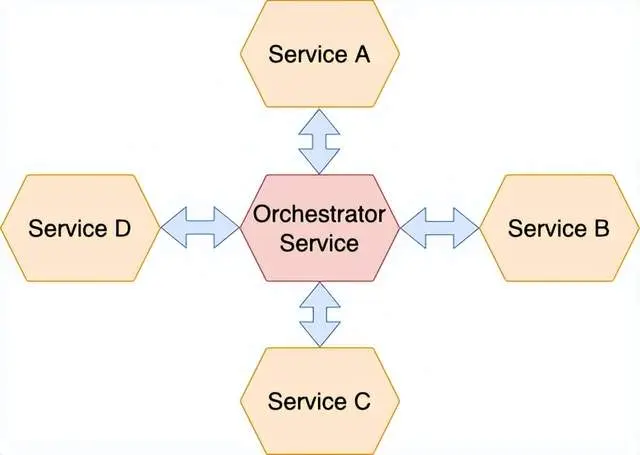
To implement a saga, it requires logic to coordinate its steps. Once a system command initiates a saga, the coordination logic must select and instruct the first saga to execute a local transaction. Once the transaction is completed, orchestration coordination will select and call the next saga participant. This process continued until the completion of the legend. If the local transaction fails, saga must execute the compensation transaction in the opposite order.
5.2 There are several methods to construct the coordination logic of saga:
Orchestration: Assigning decisions and ranking among participants in saga. They mainly communicate by exchanging events.
5.2.1 Advantages of Saga based on orchestration
Simplicity - When a business object is created, updated, or deleted, the service publishes events.
Simple dependencies - do not introduce circular dependencies.
Loose coupling - The service implements an API called by the choreographer, so it does not need to know the events published by the Saga participant.
Simplify business logic - In the saga orchestrator, the saga coordination logic is localized. Domain objects are not aware of the sagas they involve.
5.2.2 Weaknesses based on orchestration
More difficult to understand - orchestration distributes the implementation of saga among services, with each service being independent, which requires each manager to understand each service.
Circular dependencies between services - Saga participants subscribe to each other’s events, which typically results in circular dependencies.
Tightly coupled risk - Saga participants must subscribe to all events that affect them.
Orchestration - The coordination logic of a saga should be concentrated in a saga orchestrator class. During saga, the choreographer sends command messages to participants, telling them what actions to take.